
El análisis de sentimiento, también denominado minería de opinión u Opinion Mining, se centra en identificar y categorizar la carga emocional presente en datos textuales para interpretar opiniones, actitudes y estados emocionales. Este proceso se basa en modelos de machine learning y técnicas de procesamiento del lenguaje natural que permiten analizar el lenguaje a escala y convertirlo en información estructurada.
¿En qué consiste el análisis de sentimiento?
El análisis de sentimiento hace referencia al uso de procesamiento de lenguaje natural (NLP), lingüística computacional y análisis de texto (rama específica de la minería de datos) para identificar y extraer información subjetiva de los recursos.
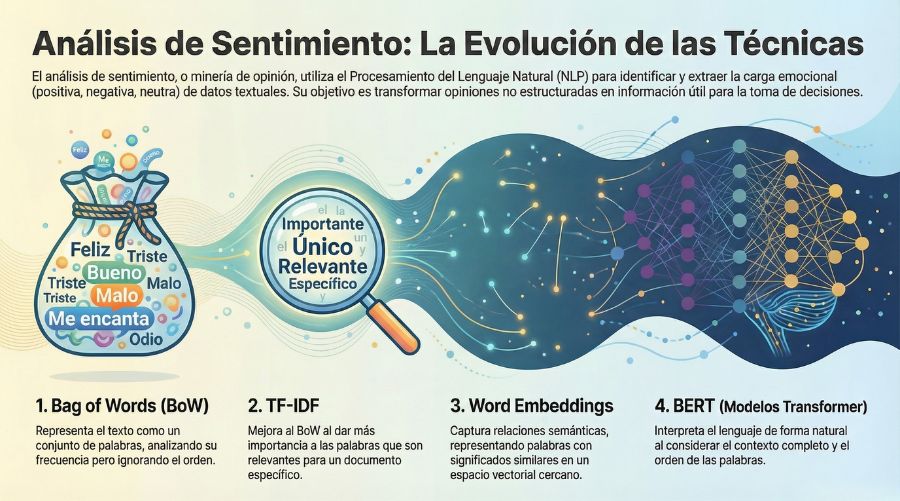
Para llevar a cabo un análisis de sentimiento se parte de conjuntos de datos de opiniones o reviews, sobre los que se aplican distintos algoritmos de representación y modelado del texto. Entre los enfoques clásicos se encuentran Bag of Words (BoW) y TF-IDF, que introduce una ponderación más informativa sobre la frecuencia de los términos. En un nivel más avanzado destacan modelos como BERT (Bidirectional Encoder Representations from Transformers), que incorporan una comprensión contextual del lenguaje.
El análisis de sentimiento se basa en técnicas de procesamiento del lenguaje natural, lingüística computacional y análisis de texto para detectar e interpretar información subjetiva presente en datos textuales
Bag of Words
Bag of Words es un método utilizado en el procesamiento del lenguaje natural para representar documentos ignorando el orden de las palabras. En este enfoque, el texto se transforma en un conjunto de términos y se analiza la presencia o frecuencia de cada uno para evaluar si contribuyen de forma general a una review positiva o negativa. A partir de esta representación, se aplica un algoritmo clasificador como KNN, que compara la muestra con otras previamente etiquetadas y asigna una clase en función de la similitud con sus vecinos más cercanos.
Este enfoque destaca por su simplicidad y por la facilidad con la que convierte texto no estructurado en vectores numéricos procesables por algoritmos de Machine Learning tradicionales. Por este motivo, Bag of Words suele emplearse como modelo inicial o línea base en proyectos de análisis de sentimiento, ya que permite validar rápidamente hipótesis y flujos de trabajo.
Sin embargo, al no capturar relaciones semánticas ni el contexto del lenguaje, presenta limitaciones importantes en textos complejos, donde la negación, la ironía o el significado implícito influyen en la interpretación. Además, el tamaño del vocabulario impacta directamente en la dimensionalidad del modelo, lo que genera representaciones dispersas en conjuntos de datos amplios. En entornos de Big Data, su uso se orienta principalmente a tareas exploratorias o educativas, sirviendo como referencia frente a técnicas más avanzadas.
Tf-idf
Tf-idf es una medida numérica que expresa lo relevante que es una palabra para un documento. El valor Tf-idf aumenta proporcionalmente al número de veces que una palabra aparece en el documento, sin embargo, es compensada por la frecuencia de la palabra en la colección de documentos, lo que permite esclarecer que algunas palabras son generalmente más comunes que otras.
Este enfoque introduce una mejora clara frente a Bag of Words, ya que reduce el peso de términos muy frecuentes que aportan poco valor semántico al análisis. Palabras comunes en el lenguaje, aunque aparezcan repetidamente, ven disminuida su influencia, mientras que términos más específicos adquieren mayor relevancia dentro del modelo. De este modo, la representación del texto resulta más informativa para tareas de clasificación.
En el contexto del análisis de sentimiento, TF-IDF permite capturar mejor aquellas palabras que caracterizan opiniones positivas o negativas dentro de un conjunto de reviews. Al combinar esta representación con algoritmos de Machine Learning supervisados, como regresión logística o máquinas de soporte vectorial, se obtienen modelos más estables y precisos que con frecuencias simples.
Aun así, TF-IDF sigue siendo una técnica basada en estadísticas de ocurrencia y no incorpora comprensión semántica ni contextual del lenguaje. El modelo no distingue el significado de una palabra según su posición o relación con otras, lo que limita su eficacia en textos complejos. Por este motivo, TF-IDF se considera un paso intermedio sólido dentro de los pipelines de procesamiento del lenguaje, especialmente útil antes de adoptar modelos contextuales más avanzados.
Word embeddings
Los word embeddings representan un avance significativo frente a los enfoques basados únicamente en frecuencias, ya que permiten capturar relaciones semánticas entre palabras. En lugar de tratar cada término como una entidad aislada, estas técnicas proyectan las palabras en un espacio vectorial continuo donde la cercanía entre vectores refleja similitudes de significado. De este modo, palabras relacionadas conceptualmente aparecen más próximas entre sí, incluso aunque no compartan una alta frecuencia conjunta en los documentos.
En el análisis de sentimiento, los embeddings permiten identificar patrones más ricos en el lenguaje, ya que el modelo empieza a reconocer asociaciones semánticas y contextuales básicas. Esto resulta especialmente relevante cuando distintas palabras expresan emociones similares sin utilizar exactamente el mismo vocabulario. A diferencia de Bag of Words o TF-IDF, esta representación reduce la dimensionalidad del problema y mejora la generalización del modelo ante textos nuevos.
Sin embargo, los word embeddings tradicionales asignan un único vector a cada palabra, independientemente del contexto en el que aparezca. Esto implica que términos con múltiples significados se representen de forma estática, lo que introduce ambigüedad en frases complejas. Aun así, estos modelos supusieron un paso intermedio clave en la evolución del procesamiento del lenguaje natural y sentaron las bases para los enfoques contextuales posteriores.
Modelos supervisados para análisis de sentimiento
Los modelos supervisados constituyen una de las aproximaciones más utilizadas en el análisis de sentimiento cuando se dispone de datos previamente etiquetados. En este enfoque, el sistema aprende a clasificar textos a partir de ejemplos donde la polaridad o categoría emocional ya está definida, lo que permite ajustar el modelo para reconocer patrones lingüísticos asociados a opiniones positivas, negativas o neutras.
Dentro de este contexto, la calidad del conjunto de entrenamiento resulta determinante. La coherencia en las etiquetas, la diversidad de ejemplos y el equilibrio entre clases influyen directamente en la capacidad del modelo para generalizar. Al combinar representaciones como TF-IDF o word embeddings con algoritmos de clasificación supervisada, se logra un equilibrio entre interpretabilidad y rendimiento, especialmente en entornos controlados.
Estos modelos destacan por su estabilidad y por la facilidad con la que pueden evaluarse mediante métricas objetivas, lo que los hace adecuados para entornos empresariales donde se requiere control sobre el comportamiento del sistema. No obstante, su dependencia de datos etiquetados limita su escalabilidad cuando el volumen de información crece rápidamente o cuando el lenguaje evoluciona con el tiempo. Por este motivo, los modelos supervisados suelen integrarse como parte de pipelines más amplios, sirviendo como base sólida antes de adoptar enfoques contextuales o híbridos de mayor complejidad.
Modelos híbridos en opinion mining
Los modelos híbridos en opinion mining surgen como respuesta a las limitaciones de los enfoques puramente estadísticos o exclusivamente basados en aprendizaje automático. Estos sistemas combinan técnicas basadas en reglas lingüísticas con modelos supervisados o representaciones vectoriales, buscando aprovechar las fortalezas de cada aproximación dentro de un mismo pipeline de análisis.
En el contexto del análisis de sentimiento, este enfoque permite introducir conocimiento experto de forma explícita mediante diccionarios, reglas semánticas o patrones lingüísticos, mientras que los modelos de Machine Learning aportan capacidad de generalización y adaptación a grandes volúmenes de datos. De esta forma, los modelos híbridos ofrecen un mayor control sobre el comportamiento del sistema, algo especialmente valorado en entornos empresariales donde la trazabilidad y la coherencia de los resultados resultan críticas.
Otra ventaja relevante de estos enfoques es su robustez frente a cambios en el lenguaje o a dominios muy específicos. Las reglas se ajustan para cubrir casos concretos, mientras que los modelos aprendidos capturan tendencias globales del corpus. Sin embargo, esta combinación incrementa la complejidad del sistema y exige un diseño cuidadoso para evitar incoherencias entre componentes. Por este motivo, los modelos híbridos se emplean habitualmente en soluciones de análisis de sentimiento maduras, donde el equilibrio entre precisión, control y escalabilidad resulta prioritario.
BERT
Para terminar, BERT o Representación de Codificador Bidireccional de Transformadores, es un algoritmo desarrollado por Google, que tiene como objetivo interpretar el lenguaje de nuestras búsquedas de una forma más natural (PNL). Entre otras cosas se diferencia de BoW en que tiene en cuenta el orden de las palabras, suposición y contexto.
Actualmente, BERT es considerado como uno de los modelos de procesamiento del lenguaje natural más influyentes y ampliamente utilizados, y tiene un impacto significativo en el campo de la investigación en NLP (procesamiento del lenguaje natural).
BERT se usa en el campo del procesamiento del lenguaje natural (NLP) para una amplia gama de tareas, incluyendo clasificación de texto, extracción de información, respuesta a preguntas o generación de texto.
Por otra parte, BERT y otros modelos avanzados de procesamiento del lenguaje natural se aplican en el ámbito médico a múltiples tareas relacionadas con el análisis de información clínica. Su uso permite automatizar la interpretación de grandes volúmenes de texto sanitario, mejorar la eficiencia de los flujos de trabajo y facilitar el acceso a conocimiento relevante para los profesionales de la salud, apoyando procesos de análisis y decisión basados en datos.
En definitiva, el análisis de sentimiento aplicado al ML transforma grandes volúmenes de lenguaje natural en información estructurada para interpretar opiniones y percepciones en entornos digitales. Este tipo de análisis es relevante cuando se trabaja con datos no estructurados procedentes de redes sociales, plataformas de opinión o canales de comunicación masivos.
Dominar estas técnicas requiere comprender su integración en arquitecturas de Big Data y su aplicación en proyectos reales, un enfoque que se trabaja de forma práctica en el Máster en Big Data, donde el análisis avanzado de datos, el Machine Learning y el procesamiento del lenguaje natural se abordan como competencias clave.