
Este trabajo esta basado en un dataset creado por Datamarket cuya muestra gratuita se puede encontrar en la plataforma kaggle, https://www.kaggle.com/datamarket/venta-de-coches

Por Javier Calviño Tilves
Alumno de la 7ª edición del Máster en Big Data y Ing. Téc. Naval
Análisis y predicción
A partir de estos datos que son una selección de anuncios de venta de coches de segunda mando provenientes de las principales plataformas de internet, y en los cuales vienen coches de todas las marcas y modelos, incluidas diversas variables de los mismos con sus diversos precios de venta.
Hemos limpiado y transformado los mismos, para posteriormente seleccionar de este gran conjunto de datos que aglutinan unas 50000 observaciones, un subconjunto nuevo de datos de unas 12000 observaciones en el que hemos pretendido hacer referencia solo a los coches que se encuentren en un rango de precios entre 6000 y 12000 euros para a posteriori hacer un estudio y análisis exploratorio con estos datos y finalmente hacer un modelo con los mismos para proceder a predecir el precio de venta de los vehículos.
Estos datos pertenecen a una muestra gratuita sin suscripción, algunos de los datos de las columnas están encriptados para cumplir con la GDPR, aunque no nos ha hecho falta utilizarlos para este trabajo.
Un modelo predictivo basado en Big Data permite estimar el precio de vehículos de segunda mano mediante variables históricas, características técnicas y patrones de mercado en tiempo real
Variables que contiene el dataset
color: Color del vehículo.
company: Web de donde se ha realizado la extracción del anuncio
(encriptado).Estará disponible tras la suscripción al dataset.
country: País donde se vende el vehículo.
dealer: Vendedor del vehículo. En el caso de vendedores particulares (no concesionarios), esta información está encriptada en el dataset para cumplir con la GDPR.
fuel: Tipo de combustible del vehículo (diésel, gasolina, eléctrico, híbrido).
insert_date: Fecha de extracción de la información.
is_professional: Indica si el vendedor es profesional (un concesionario).
kms: Kilometraje del vehículo.
make: Marca del coche.
model: Modelo del vehículo.
photos: Número de fotografías del vehículo disponibles en el anuncio.
power: Potencia del vehículo.
price: Precio de venta del vehículo.
price_financed: Precio si el coche está financiado.
province: Provincia donde se vende el vehículo.
publish_date: Fecha de publicación del anuncio.
shift: Tipo de cambio (Automático/Manual).
url: Url del coche de segunda mano en venta.
version: Versión del vehículo.
year: Año de fabricación del vehículo.
Exposición del Estudio
Se realizan las siguientes tareas:
-CARGA, LIMPIEZA, TRANSFORMACION Y FILTRADO DE DATOS A PARTIR DEL CONJUNTO ORIGINAL.
-ANALISIS EXPLORATORIO DE LOS DATOS A PARTIR DEL SUBCONJUNTO DE DATOS.
-MODELO PREDICCION PRECIO DE VENTA CREADO A PARTIR DEL SUBCONJUNTO DE DATOS.
Carga, limpieza, transformación y filtrado de datos a partir del conjunto original
library(tidyverse) |
dat <- read.csv("d:/Users/USUARIO/Desktop/archive/coches_2_mano.csv") str(dat) |
## 'data.frame': 50000 obs. of 21 variables: |
Eliminamos variables que no vamos a considerar en nuestro estudio por no ser significativas:
dat$url <- NULL dat$company <- NULL dat$photos <- NULL dat$dealer <- NULL dat$insert_date <- NULL dat$country <- NULL dat$version <- NULL dat$publish_date <- NULL dat$color <- NULL glimpse(dat) |
## Rows: 50,000 |
Ahora en vista de su visualización y estructura trataremos de limpiar los datos con caracteres especiales.
En lugar de usar expresiones regulares para eliminar esos caracteres especiales, simplemente los vamos a convertir a ASCII, lo que eliminará los acentos, pero conservará las letras.
dat$fuel <- iconv(dat$fuel, from = 'UTF-8', to = 'ASCII//TRANSLIT') dat$model <-iconv(dat$model, from = 'UTF-8', to = 'ASCII//TRANSLIT') dat$shift <- iconv(dat$shift, from = 'UTF-8', to = 'ASCII//TRANSLIT') dat$province <- iconv(dat$province, from = 'UTF-8', to = 'ASCII//TRANSLIT') kable(head(dat,6)) |
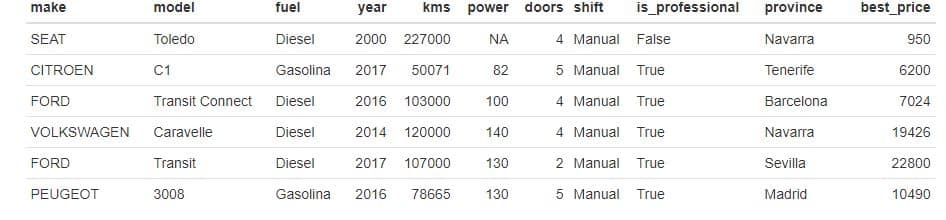
Ahora vamos a realizar la imputación de los valores de los NA de la variable “power” que nos queda para que nos halle los valores faltantes en dicha variable.
Escogemos el sistema de imputación KNN de la librería VIM (Visualización e imputación de valores perdidos), para resolverlo.
dat2<-kNN(datm,variable ="power",k=sqrt(nrow(dat))) dat2$power_imp <- NULL |
Comprobamos ahora si quedan rastro de los NAs en nuestros datos.
colSums(is.na(dat2)) |
…
## make model fuel year kms ## 0 0 0 0 0 ## power doors shift is_professional province ## 0 0 0 0 0 ## best_price ## 0 |
…
kable(head(dat2,6)) |

Y vemos que ya no tenemos NAs en nuestras variables.
Vamos a reducir nuestro dataset con el objetivo de determinar solamente los coches que estén en una franja de precios entre 6000 y 12000 euros.
datfilter <- dat2%>%filter(best_price<=12000 & best_price>6000) |
Ahora vamos a considerar como factores las variables que correspondan en nuestros datos.
datfilter$make <- as.factor(datfilter$make) datfilter$model <- as.factor(datfilter$model) datfilter$fuel <- as.factor(datfilter$fuel) datfilter$shift <- as.factor(datfilter$shift) datfilter$is_professional <- as.factor(datfilter$is_professional) datfilter$province <- as.factor(datfilter$province)%>%fct_recode("A Coruña"="A Coruna") str(datfilter) |
…
## 'data.frame': 12800 obs. of 11 variables: ## $ make : Factor w/ 53 levels "ABARTH","ALFA ROMEO",..: 9 14 35 15 33 30 13 13 14 9 ... ## $ model : Factor w/ 483 levels "100","106","108",..: 82 438 19 119 323 123 331 174 80 83 ... ## $ fuel : Factor w/ 7 levels "Diesel","Electrico",..: 5 1 5 1 5 5 1 1 5 5 ... ## $ year : int 2017 2016 2016 2012 2016 2001 2017 2010 2018 2019 ... ## $ kms : int 50071 103000 78665 203000 77000 169450 101623 135000 53000 13000 ... ## $ power : int 82 100 130 150 80 306 95 120 125 68 ... ## $ doors : int 5 4 5 5 5 2 5 5 5 5 ... ## $ shift : Factor w/ 2 levels "Automatico","Manual": 2 2 2 2 2 1 2 2 2 2 ... ## $ is_professional: Factor w/ 2 levels "False","True": 2 2 2 1 1 2 2 1 2 2 ... ## $ province : Factor w/ 52 levels "A Coruña","Alava",..: 45 10 32 10 10 33 32 36 4 21 ... ## $ best_price : int 6200 7024 10490 8200 6300 6900 9500 8000 11380 10990 ... |
Vamos a escoger las variables numéricas para hacer la matriz de correlación y comprobar que las variables no estén muy correlacionadas entre si.
dat3 <- datfilter%>%select(c("year", "kms", "power", "doors")) |
dat.cor <- cor(dat3, method = "pearson") corrplot(dat.cor, method = "shade", shade.col = NA, tl.col = "black", tl.srt = 45, addCoef.col = "black", addcolorlabel = "no", order = "AOE") |

Como se puede ver en la matriz las variables independientes entre si no exceden el 0.7 de correlación por tanto no se muestran problemas en este sentido.
Vamos también a cambiar a factor la variable doors y también el nombre de sus niveles:
datfilter$doors <- as.factor(datfilter$doors) levels(datfilter$doors) <- c("2p", "3p", "4p", "5p") str(datfilter) |
….
## 'data.frame': 12800 obs. of 11 variables: ## $ make : Factor w/ 53 levels "ABARTH","ALFA ROMEO",..: 9 14 35 15 33 30 13 13 14 9 ... ## $ model : Factor w/ 483 levels "100","106","108",..: 82 438 19 119 323 123 331 174 80 83 ... ## $ fuel : Factor w/ 7 levels "Diesel","Electrico",..: 5 1 5 1 5 5 1 1 5 5 ... ## $ year : int 2017 2016 2016 2012 2016 2001 2017 2010 2018 2019 ... ## $ kms : int 50071 103000 78665 203000 77000 169450 101623 135000 53000 13000 ... ## $ power : int 82 100 130 150 80 306 95 120 125 68 ... ## $ doors : Factor w/ 4 levels "2p","3p","4p",..: 4 3 4 4 4 1 4 4 4 4 ... ## $ shift : Factor w/ 2 levels "Automatico","Manual": 2 2 2 2 2 1 2 2 2 2 ... ## $ is_professional: Factor w/ 2 levels "False","True": 2 2 2 1 1 2 2 1 2 2 ... ## $ province : Factor w/ 52 levels "A Coruña","Alava",..: 45 10 32 10 10 33 32 36 4 21 ... ## $ best_price : int 6200 7024 10490 8200 6300 6900 9500 8000 11380 10990 ... |
A continuación para el desarrollo de nuestros análisis vamos a crear una nueva variable que junte, make con model.
datc <- datfilter%>%mutate(unite(datfilter,make_model,c(1:2),sep="_", remove=F)) datc$make_model <- as.factor(datc$make_model) |
Análisis exploratorio de los datos a partir del subconjunto de datos
Mostramos la tabla con la cantidad de anuncios ofertados en función de la marca de coches dentro del rango solicitado y visualizamos los 10 últimos (más ofertados).
table1 <- kable(sort(table(datc$make))) tail(table1,10) |
….
## [1] "|SEAT | 664|" "|AUDI | 679|" "|FIAT | 697|" ## [4] "|CITROEN | 835|" "|BMW | 874|" "|RENAULT | 918|" ## [7] "|OPEL | 927|" "|PEUGEOT | 937|" "|FORD | 973|" ## [10] "|VOLKSWAGEN | 1235|" |
Asimismo también mostramos la tabla con la cantidad de anuncios ofertados por modelo de coche también dentro de este rango y visualizamos los 10 últimos (más ofertados).
table2 <- kable(sort(table(datc$make_model))) tail(table2,10) |
…
## [1] "|VOLKSWAGEN_Polo | 236|" ## [2] "|BMW_Serie 1 | 237|" ## [3] "|OPEL_Astra | 244|" ## [4] "|RENAULT_Megane | 245|" ## [5] "|RENAULT_Clio | 251|" ## [6] "|FORD_Focus | 273|" ## [7] "|FIAT_500 | 296|" ## [8] "|SEAT_Ibiza | 297|" ## [9] "|BMW_Serie 3 | 322|" ## [10] "|VOLKSWAGEN_Golf | 361|" |
A continuación vamos a visualizar el TOP 10 de la cantidad de anuncios ofertados por marca de coche dentro de ese rango.
datft <- datc %>% mutate(make_redux=fct_lump_n(make, n=10, other_level = "OTHER")) dropft <- datft$make_redux%>%droplevels("OTHER") dropt <- as.data.frame(dropft) dropl <- na.omit(dropt) |
….
Top10_marca <- count(dropl, dropft) %>% ggplot(aes(reorder(dropft,-n), n,fill=dropft,text=paste("Marca:", reorder(dropft,-n), " ", "Count:", n, " ")))+geom_col()+ theme(axis.text.x = element_text(face = "bold", family = "Courier New",size = 9,color = "azure4"), axis.text.y = element_text(face= "italic", family = "Courier",color="azure4", size = 9))+labs(x='MARCA DE COCHES', y='Numero de Coches ofertados por Marca')+ ggtitle('TOP 10 COCHES A LA VENTA POR MARCA')+ theme(legend.title = element_blank()) ggplotly(Top10_marca,tooltip=c("text")) |

Después vamos a visualizar el TOP 10 de la cantidad de anuncios ofertados por marca y modelo de coches dentro de ese rango.
datft2 <- datc %>% mutate(model_redux=fct_lump_n(make_model, n=10, other_level = "Other")) dropft2 <- datft2$model_redux%>%droplevels("Other") dropt2 <- as.data.frame(dropft2) dropl2 <- na.omit(dropt2) |
….
Top10_marcmod <- count(dropl2, dropft2) %>% ggplot(aes(reorder(dropft2,n), n,fill=dropft2,text=paste("Marca+model:", reorder(dropft2,-n), " ", "Count:", n, " ")))+geom_col()+coord_flip()+ theme(axis.text.x = element_text(face = "bold", family = "Courier New",size = 9,color = "azure4"), axis.text.y = element_text(face= "italic", family = "Courier",color="azure4", size = 9))+labs(x='MARCA DE COCHES', y='Numero de Coches ofertados por Marca')+ ggtitle('TOP 10 COCHES A LA VENTA POR MARCA Y MODELO')+ theme(legend.title = element_blank()) ggplotly(Top10_marcmod,tooltip=c("text")) |

También veremos el promedio de precio de los coches eléctricos que hay en la relación por orden, marca y modelo de los mismos.
med_elect <- datc%>% filter(fuel=="Electrico")%>% group_by(make_model,fuel)%>% summarise(avgelect=round(mean(`best_price`)))%>% ggplot(aes(reorder(make_model,-avgelect),avgelect,fill=avgelect,text=paste("Marca_model:", reorder(make_model,-avgelect), " ", "avgprice:", avgelect, " ")))+geom_col()+ theme(axis.text.x = element_text(face = "bold", family = "Courier New",size = 9,angle=45,color = "azure4"), axis.text.y = element_text(face= "italic", family = "Courier",color="azure4", size = 9))+labs(x='MARCA Y MODELO', y='Promedio Precio Coches Electricos')+ ggtitle('PRECIOS DE COCHES ELECTRICOS POR MARCA Y MODELO')+ theme(legend.title = element_blank()) |
…
## `summarise()` has grouped output by 'make_model'. You can override using the `.groups` argument. |
….
ggplotly(med_elect,tooltip=c("text")) |

Vamos a ver ahora el promedio de precios por marca de los coches ofertados de segunda mano de nuestros datos.
gdat2avg <- datc%>% group_by(make)%>% summarise(totalaverage=round(mean(`best_price`))) |
….
treemap(dat2avg, index = c("make","totalaverage"), vSize = "totalaverage", type = "index", fontsize.labels=7,fontface.labels= c("bold.italic","bold"),algorithm="pivotSize", align.labels = list(c("center","center"),c("right","bottom")),title="PROMEDIO DE PRECIOS POR MARCA DE COCHES OFERTADOS") |

Vamos a ver ahora el promedio de precios por marca de los coches ofertados de segunda mano de nuestros datos.
gdat2avg <- datc%>% group_by(make)%>% summarise(totalaverage=round(mean(`best_price`))) |
….
treemap(dat2avg, index = c("make","totalaverage"), vSize = "totalaverage", type = "index", fontsize.labels=7,fontface.labels= c("bold.italic","bold"),algorithm="pivotSize", align.labels = list(c("center","center"),c("right","bottom")),title="PROMEDIO DE PRECIOS POR MARCA DE COCHES OFERTADOS") |


Vamos ahora a determinar el porcentaje de coches por tipo de fuel o combustible determinado por cada provincia que ofrece la venta de vehículos.
f_fuel <- datc%>% group_by(province,fuel)%>% summarise(count =n())%>% mutate(perc_fuel= (count/sum(count))*100) |
….
## `summarise()` has grouped output by 'province'. You can override using the `.groups` argument. |
…
fuel <- ggplot(f_fuel,aes(x=province,y=perc_fuel,fill=fuel, label=scales::percent_format(accuracy=0.01,scale=1,suffix="%")(perc_fuel), text=paste('percent', scales::percent_format(accuracy=0.01,scale=1,suffix="%")(perc_fuel))))+ geom_bar(position="fill",stat="identity")+scale_y_continuous(labels=percent_format())+ theme(axis.text.x = element_text(face = "bold", family = "Courier New",angle=90,size = 9,vjust=0.5,color = "azure4"), axis.text.y = element_text(face= "italic", family = "Courier",color="azure4", size = 9))+labs(x='PROVINCIA', y='Porcentaje Fuel/Provincia')+ ggtitle('PORCENTAJE DE COCHES POR TIPO DE FUEL Y PROVINCIA')+ theme(legend.title = element_blank()) ggplotly(fuel,tooltip=c("text","province","fuel")) |

Asimismo vamos a determinar el porcentaje de coches por tipo de cambio determinado por cada provincia que ofrece la venta de vehículos.
s_shift <- datc%>% group_by(province,shift)%>% summarise(count =n())%>% mutate(perc_shift= (count/sum(count))*100) |
….
## `summarise()` has grouped output by 'province'. You can override using the `.groups` argument. |
…
shift <- ggplot(s_shift,aes(x=province,y=perc_shift,fill=shift, label=scales::percent_format(accuracy=0.01,scale=1,suffix="%")(perc_shift), text=paste('percent', scales::percent_format(accuracy=0.01,scale=1,suffix="%")(perc_shift))))+ geom_bar(position="fill",stat="identity")+scale_y_continuous(labels=percent_format())+ theme(axis.text.x = element_text(face = "bold", family = "Courier New",angle=90,size = 9,vjust=0.5,color = "azure4"), axis.text.y = element_text(face= "italic", family = "Courier",color="azure4", size = 9))+labs(x='PROVINCIA', y='Porcentaje Tipo de Cambio/Provincia')+ ggtitle('PORCENTAJE DE COCHES POR TIPO DE CAMBIO Y PROVINCIA')+ theme(legend.title = element_blank()) ggplotly(shift,tooltip=c("text","province","shift")) |

También vamos a determinar el porcentaje de coches en función de si el que lo vende es profesional (concesionario) o particular dentro de cada provincia que oferta estos vehículos.
datc$is_professional <- factor(datc$is_professional, labels=c("No Profesional","Profesional")) p_isprof <- datc%>% group_by(province,is_professional)%>% summarise(count =n())%>% mutate(perc_isprof= (count/sum(count))*100) |
….
## `summarise()` has grouped output by 'province'. You can override using the `.groups` argument. |
…
isprof <- ggplot(p_isprof,aes(x=province,y=perc_isprof,fill=is_professional, label=scales::percent_format(accuracy=0.01,scale=1,suffix="%")(perc_isprof), text=paste('percent', scales::percent_format(accuracy=0.01,scale=1,suffix="%")(perc_isprof))))+ geom_bar(position="fill",stat="identity")+scale_y_continuous(labels=percent_format())+ theme(axis.text.x = element_text(face = "bold", family = "Courier New",angle=90,size = 9,vjust=0.5,color = "azure4"), axis.text.y = element_text(face= "italic", family = "Courier",color="azure4", size = 9))+labs(x='PROVINCIA', y='Porcentaje Tipo de Vendedor/ Provincia')+ ggtitle('PORCENTAJE DE COCHES POR TIPO DE VENDEDOR Y PROVINCIA')+ theme(legend.title = element_blank()) ggplotly(isprof,tooltip=c("text","province","is_professional")) |

Vamos a visualizar ahora el porcentaje total por tipo de combustible de los coches de segunda mano.
dat4count <- as.data.frame(table(datc$fuel))%>% mutate(porcentaje=scales::percent(Freq/sum(Freq),accuracy=0.01)) dat4count |
….
## Var1 Freq porcentaje ## 1 Diesel 8034 62.77% ## 2 Eléctrico 71 0.55% ## 3 Gas licuado (GLP) 61 0.48% ## 4 Gas natural (CNG) 24 0.19% ## 5 Gasolina 4457 34.82% ## 6 Hibrido 150 1.17% ## 7 Hibrido enchufable 3 0.02% |
…
totalfuel <- plot_ly(dat4count, labels = ~Var1, values = ~Freq, type = 'pie') totalfuel <- totalfuel %>% layout(title = 'TOTAL FUEL COCHES 2ª MANO', xaxis = list(showgrid = FALSE, zeroline = FALSE, showticklabels = FALSE), yaxis = list(showgrid = FALSE, zeroline = FALSE, showticklabels = FALSE)) totalfuel |

Seguidamente veremos el porcentaje total por tipo de cambio de los coches recogidos en nuestros datos.
dat4count2 <- as.data.frame(table(datc$shift))%>% mutate(porcentaje=scales::percent(Freq/sum(Freq),accuracy=0.01)) dat4count2 |
….
## Var1 Freq porcentaje ## 1 Automático 2221 17.35% ## 2 Manual 10579 82.65% |
…
pie3D(dat4count2$Freq,labels=dat4count2$porcentaje,main="TIPO DE CAMBIO UTILIZADO COCHES DE SEGUNDA MANO",radius=0.95,explode = 0.1,labelcex=0.7,theta=55*pi/180,height=0.1) par(xpd=TRUE) legend(1,0.7,legend=dat4count2$Var1,cex=0.7,yjust=0.2, xjust = -0.1, fill = rainbow(length(dat4count2$porcentaje))) |

A continuación veremos el porcentaje total de los vendedores que ofertan coches de segunda mano, según sean profesionales (concesionario) o particulares.
dat4count3 <- as.data.frame(table(datc$is_professional))%>% mutate(porcentaje=scales::percent(Freq/sum(Freq),accuracy=0.01)) dat4count3 |
….
## Var1 Freq porcentaje ## 1 No Profesional 3948 30.84% ## 2 Profesional 8852 69.16% |
…
pie3D(dat4count3$Freq,labels=dat4count3$porcentaje,main="VENDEDOR PROFESIONAL O PARTICULAR",radius=0.95,explode = 0.1,labelcex=0.7,theta=55*pi/180,height=0.1) par(xpd=TRUE) legend(1,0.7,legend=dat4count3$Var1,cex=0.7,yjust=0.2, xjust = -0.1, fill = rainbow(length(dat4count3$porcentaje))) |

Vamos a visualizar también la fecha media de fabricación por marca de los vehículos.
dat4avg <- datc%>% group_by(make)%>% summarise(avgyear=round(mean(`year`),digits=0)) |
..
Fechmed <- ggplot(dat4avg,aes(x=reorder(make,desc(factor(avgyear))),y=factor(avgyear),text=paste("Marca:", reorder(make,desc(factor(avgyear))), " ", "Avgyear:", factor(avgyear), " ")))+geom_col(fill="blue")+ theme(axis.text.x = element_text(face = "bold", family = "Courier New",angle=90,size = 9,color = "azure4"), axis.text.y = element_text(face= "italic", family = "Courier",color="azure4", size = 9))+labs(x='MARCA DE COCHES', y='Años')+ ggtitle('FECHA MEDIA DE FABRICACION POR MARCA DE VEHICULOS')+ theme(legend.title = element_blank()) ggplotly(Fechmed,tooltip=c("text")) |

También veremos la frecuencia del kilometraje de los coches de segunda mano que están en venta.
freqkilm <- ggplot(datc, aes(x=kms)) + geom_histogram(col="black", fill="purple", alpha = .2) + labs(title="HISTOGRAMA KMS", x="KMS", y="Frequency")+ xlim(c(0,500000)) ggplotly(freqkilm) |

Modelo predicción precio de venta creado a partir del subconjunto de datos
División de los datos de entrenamiento y prueba
Creamos las particiones de entrenamiento y prueba, 70% y 30% respectivamente.
set.seed(85) partition <- createDataPartition(y=datfilter$best_price, p=0.7, list=F) trainingSet <- datfilter[partition,] testingSet <- datfilter[-partition,] |
Modelización de datos.
Vamos a realizar esta modelización a través de 4 modelos diferentes con sus correspondientes algoritmos, como son:
Regresión lineal (LM), ExtraGradientBoosting (XGBOOST), Random Forest (RFOREST) y KNN.
Procedemos a continuación ahora a hacer la validación cruzada 10 veces con 3 repeticiones.
trainControl <- trainControl(method="repeatedcv", number = 10,repeats=3) metric <- "RMSE" |
Ahora procedemos a realizar el entrenamiento con los modelos anteriormente dichos:
LM
set.seed(85) lm <- train(best_price~., data = trainingSet, method = "lm", metric=metric, preProc=c("center", "scale"),trControl=trainControl) |
XGBOOST
set.seed(85) xgbst <- train(best_price~., data = trainingSet, method = "xgbLinear", metric=metric,preProc=c("center", "scale"),trControl=trainControl) |
RFOREST
set.seed(85) rforest <- train(trainingSet[,1:10],trainingSet[,11], method = "ranger", metric=metric,num.trees=100, preProc=c("center", "scale"),trControl=trainControl,respect.unordered.factors = TRUE) |
KNN
set.seed(85) knn <- train(best_price~., data = trainingSet, method = "knn", metric=metric, preProc=c("center", "scale"),trControl=trainControl) |
Evaluación y Comparación de los algoritmos que utilizamos
set.seed(85) Results <- resamples(list(LM=lm, XGBOOST= xgbst, RFOREST=rforest, KNN=knn)) summary(Results) |
..
## ## Call: ## summary.resamples(object = Results) ## ## Models: LM, XGBOOST, RFOREST, KNN ## Number of resamples: 30 ## ## MAE ## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's ## LM 944.4070 976.0758 983.9539 987.2817 1000.1184 1023.6205 0 ## XGBOOST 851.6686 866.8550 875.0349 879.3448 891.7567 927.9521 0 ## RFOREST 881.6983 907.8964 920.8578 922.4130 941.0051 963.8679 0 ## KNN 1198.1311 1247.0183 1256.0821 1256.4307 1269.4564 1290.5144 0 ## ## RMSE ## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's ## LM 1203.511 1267.361 1283.736 1318.221 1328.411 1617.281 0 ## XGBOOST 1067.448 1105.380 1122.026 1126.278 1143.300 1193.735 0 ## RFOREST 1121.472 1169.630 1191.168 1190.116 1209.772 1244.293 0 ## KNN 1470.157 1519.602 1529.158 1532.347 1558.090 1572.528 0 ## ## Rsquared ## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's ## LM 0.2883438 0.3932986 0.4070434 0.4042316 0.4338683 0.4775843 0 ## XGBOOST 0.5021648 0.5361225 0.5520001 0.5477383 0.5629324 0.5896132 0 ## RFOREST 0.4457864 0.4765231 0.4929557 0.4949056 0.5055908 0.5563069 0 ## KNN 0.1327529 0.1548898 0.1707678 0.1716328 0.1836352 0.2241544 0 |
..
dotplot(Results) |

Como puede verse los 2 algoritmos con diferencia mas destacados (RMSE) en el enteramiento son XGBOOST y RANDOM FOREST, destacando el primero sobre el segundo ligeramente.
Optimización de Parámetros
Vamos a optimizar los modelos con los resultados de RMSE mas bajos, en este caso muy cercanos, los modelos de XGBOOST y RANDOM FOREST.
Para poder aplicar los hiperparametros a los modelos que hemos dicho, vamos a visualizar los hiperparametros óptimos que dieron los resultados anteriores, y vamos a establecer nuevos hiperparametros de referencia en torno a estos para ver si podemos mejorar los resultados anteriores. Así pues:
print(xgbst) |
..
## eXtreme Gradient Boosting ## ## 8961 samples ## 10 predictor ## ## Pre-processing: centered (599), scaled (599) ## Resampling: Cross-Validated (10 fold, repeated 3 times) ## Summary of sample sizes: 8065, 8065, 8065, 8066, 8065, 8064, ... ## Resampling results across tuning parameters: ## ## lambda alpha nrounds RMSE Rsquared MAE ## 0e+00 0e+00 50 1158.403 0.5234567 920.2527 ## 0e+00 0e+00 100 1137.440 0.5385180 892.8081 ## 0e+00 0e+00 150 1131.783 0.5434236 882.4207 ## 0e+00 1e-04 50 1158.403 0.5234567 920.2527 ## 0e+00 1e-04 100 1137.440 0.5385180 892.8081 ## 0e+00 1e-04 150 1131.813 0.5433997 882.4151 ## 0e+00 1e-01 50 1158.214 0.5236407 919.9824 ## 0e+00 1e-01 100 1135.979 0.5396901 891.6553 ## 0e+00 1e-01 150 1130.482 0.5444375 880.8093 ## 1e-04 0e+00 50 1157.765 0.5239829 919.5535 ## 1e-04 0e+00 100 1135.751 0.5398620 891.5633 ## 1e-04 0e+00 150 1130.309 0.5446285 880.6287 ## 1e-04 1e-04 50 1157.765 0.5239829 919.5535 ## 1e-04 1e-04 100 1135.751 0.5398620 891.5633 ## 1e-04 1e-04 150 1130.309 0.5446285 880.6287 ## 1e-04 1e-01 50 1158.071 0.5236952 919.6146 ## 1e-04 1e-01 100 1136.372 0.5393403 892.0102 ## 1e-04 1e-01 150 1129.513 0.5452190 880.3518 ## 1e-01 0e+00 50 1157.179 0.5246009 919.9074 ## 1e-01 0e+00 100 1132.378 0.5427577 890.4943 ## 1e-01 0e+00 150 1126.466 0.5475931 879.4161 ## 1e-01 1e-04 50 1157.179 0.5246009 919.9074 ## 1e-01 1e-04 100 1132.378 0.5427577 890.4943 ## 1e-01 1e-04 150 1126.278 0.5477383 879.3448 ## 1e-01 1e-01 50 1156.893 0.5248479 919.8702 ## 1e-01 1e-01 100 1132.363 0.5427738 890.4335 ## 1e-01 1e-01 150 1126.708 0.5473711 879.2831 ## ## Tuning parameter 'eta' was held constant at a value of 0.3 ## RMSE was used to select the optimal model using the smallest value. ## The final values used for the model were nrounds = 150, lambda = 0.1, alpha ## = 1e-04 and eta = 0.3. |
..
print(rforest) |
..
## Random Forest ## ## 8961 samples ## 10 predictor ## ## Pre-processing: centered (3), scaled (3), ignore (7) ## Resampling: Cross-Validated (10 fold, repeated 3 times) ## Summary of sample sizes: 8065, 8065, 8065, 8066, 8065, 8064, ... ## Resampling results across tuning parameters: ## ## mtry splitrule RMSE Rsquared MAE ## 2 variance 1196.389 0.4975000 954.5151 ## 2 extratrees 1297.173 0.4266905 1059.0382 ## 6 variance 1190.116 0.4949056 922.4130 ## 6 extratrees 1216.945 0.4721816 951.1000 ## 10 variance 1213.070 0.4774561 931.7894 ## 10 extratrees 1217.057 0.4718081 941.6542 ## ## Tuning parameter 'min.node.size' was held constant at a value of 5 ## RMSE was used to select the optimal model using the smallest value. ## The final values used for the model were mtry = 6, splitrule = variance ## and min.node.size = 5. |
Después de distintas experimentaciones nos hemos decantado por los siguientes hiperparametros para mejorar los modelos establecidos.
XGBOOST
hiperparametrosXG <- expand.grid(nrounds=200, eta=0.3, lambda=1, alpha = seq(0.005,0.05,0.005)) |
…
set.seed(85) xgbst_opt <- train(best_price~., data = trainingSet, method = "xgbLinear", metric=metric,tuneGrid=hiperparametrosXG,preProc=c("center","scale"),trControl=trainControl) |
RFOREST
hiperparametrosRF <- expand.grid(mtry = c(1,3,4,6,7,10), min.node.size = c( 3,5,7,10,25,50,75,100), splitrule = "variance") |
..
set.seed(85) rf_opt <- train(trainingSet[,1:10],trainingSet[,11], method = "ranger", metric=metric,num.trees=500,tuneGrid=hiperparametrosRF, preProc=c(«center», «scale»),trControl=trainControl,respect.unordered.factors = TRUE) |
Comprobamos los resultados para evaluar los algoritmos ya optimizados:
set.seed(85) Results <- resamples(list(XGBOOST=xgbst_opt, RFOREST= rf_opt)) summary(Results) |
…
## ## Call: ## summary.resamples(object = Results) ## ## Models: XGBOOST, RFOREST ## Number of resamples: 30 ## ## MAE ## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's ## XGBOOST 829.9863 855.3278 868.9967 869.5923 875.5534 906.5819 0 ## RFOREST 889.2853 908.7524 921.5192 922.5166 935.1776 962.8692 0 ## ## RMSE ## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's ## XGBOOST 1058.792 1107.208 1119.675 1118.304 1135.471 1170.046 0 ## RFOREST 1118.245 1155.510 1177.678 1173.866 1191.420 1233.721 0 ## ## Rsquared ## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's ## XGBOOST 0.5076065 0.5408314 0.5525082 0.5541237 0.5658952 0.5960690 0 ## RFOREST 0.4623398 0.4957587 0.5083531 0.5103533 0.5255308 0.5632897 0 |
..
dotplot(Results) |

Como vemos después de optimizar los algoritmos, sigue siendo XGBOOST con un menor RMSE el mejor algoritmo de la relación, el cual ha mejorado con respecto al anterior dato del mismo, habiendo también una mejoría mucho mas leve para RANDOM FOREST.
Por lo tanto realizamos la predicción para el modelo de XGBOOST y hallamos su RMSE con respecto a nuestro conjunto de test (prueba).
predictions <- predict(xgbst_opt,testingSet) RMSE(testingSet$best_price, predictions) |
…
## [1] 1138.334 |
Como vemos nos sale un RMSE similar o cercano al que nos daba en el entrenamiento.
Plot predictions vs test data.
plot <-testingSet %>% ggplot(aes(best_price, predictions))+ geom_point(position="jitter",alpha=0.5) + stat_smooth(aes(colour='black')) + xlab('Actual valor best_price') + ylab('Valor predicho de best_price')+ theme_bw() ggplotly(plot) |
…
## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")' |

Plot marcas precio real vs precio predicho
dat5avg <- testingSet%>% cbind(predictions)%>% group_by(make)%>% summarise(real_price=round(mean(`best_price`)),pred_price=round(mean(`predictions`))) |
…
plotvscomp <- dat5avg%>% gather(type_avg,avgprice,c(real_price, pred_price))%>% ggplot(aes(x=make,y=avgprice,color=type_avg))+ geom_point()+theme(axis.text.x = element_text(face = "bold", family = "Courier New",angle=90,size = 9,vjust=0.5,color = "azure4"), axis.text.y = element_text(face= "italic", family = "Courier",color="azure4", size = 9))+labs(x='MARCA', y='PROMEDIO PRECIO')+ ggtitle('REAL VS PREDICCION-PROMEDIOS POR MARCA')+ theme(legend.title = element_blank()) ggplotly(plotvscomp) |

Ve los gráficos interactivos aquí.